50 à 150 Go
de fichiers par collaborateur dans Microsoft 365, le patrimoine documentaire à qualifier
Gr33t, mesures clients
Sélection manuelle, mise à jour permanente, expertise mobilisée pour le bénéfice des autres : la qualification documentaire à la main ne tient pas dans la durée. Gr33t pre-RAG la remplace par un processus automatisé, piloté par règles métier, qui prépare une matière prête pour le RAG, qualifiée, à jour quotidiennement, et 10 fois plus frugale.
de fichiers par collaborateur dans Microsoft 365, le patrimoine documentaire à qualifier
Gr33t, mesures clients
coût d'un RAG entreprise « en force » (indexation + stockage vectoriel + reranking)
Gr33t, modélisation 2026
plus de documents traités par le RAG Microsoft que nécessaire
Gr33t, mesures clients
du volume documentaire effectivement utile au RAG, sur des bases bien qualifiées
Gr33t, cas Lecko (3 852 documents retenus sur 250 000 indexés)
Pour qu'un agent IA réponde pertinemment, il doit s'appuyer sur des sources sélectionnées. La plupart des projets RAG commencent donc par demander aux experts métiers de désigner les documents à indexer.
Cela part d'une intention juste. Mais cela bute sur un obstacle que vingt ans de Knowledge Management ont rendu visible. Demander à un collaborateur de qualifier ses documents prend du temps, du temps qu'il n'a pas, sur un sujet dont les bénéficiaires sont les autres. Au démarrage, certains font l'effort. Au bout de six mois, presque plus personne. Les sources stagnent, l'IA répond avec des données obsolètes, la pertinence se dégrade.
Le verrou n'est pas une question de volonté. C'est une question d'échelle et de discipline dans la durée. Une qualification documentaire à grande échelle ne peut plus être un acte humain individuel. Elle doit être un processus automatique, piloté par des règles définies une fois, qui s'appliquent à tous les documents et se mettent à jour quotidiennement.
C'est exactement le pivot que Gr33t pre-RAG opère.

Par défaut, un LLM (GPT, Opus, Gemini, Mistral) s'appuie sur ses connaissances générales : celles disponibles au moment de son entraînement. On peut lui injecter quelques documents dans sa fenêtre de contexte, mais celle-ci reste limitée à quelques milliers de pages, insuffisant pour le patrimoine documentaire d'une entreprise.
Pour qu'il mobilise la connaissance interne, on utilise le RAG : on extrait le contenu des documents, on les découpe en chunks, on les vectorise via un modèle d'embedding, et on stocke ces vecteurs. À chaque requête, le système identifie les passages les plus pertinents et les réinjecte dans le contexte du LLM pour formuler la réponse.
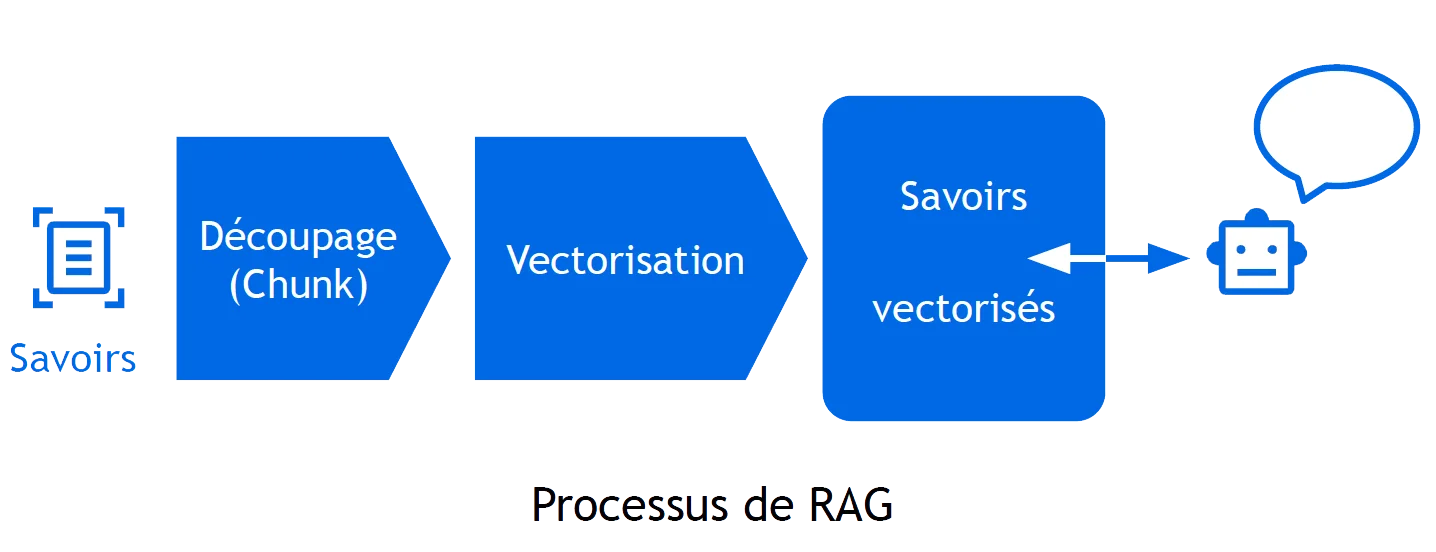
Toute la qualité d'un RAG dépend donc de ce qui rentre dans le pipeline. Et c'est précisément là que la plupart des projets buttent.
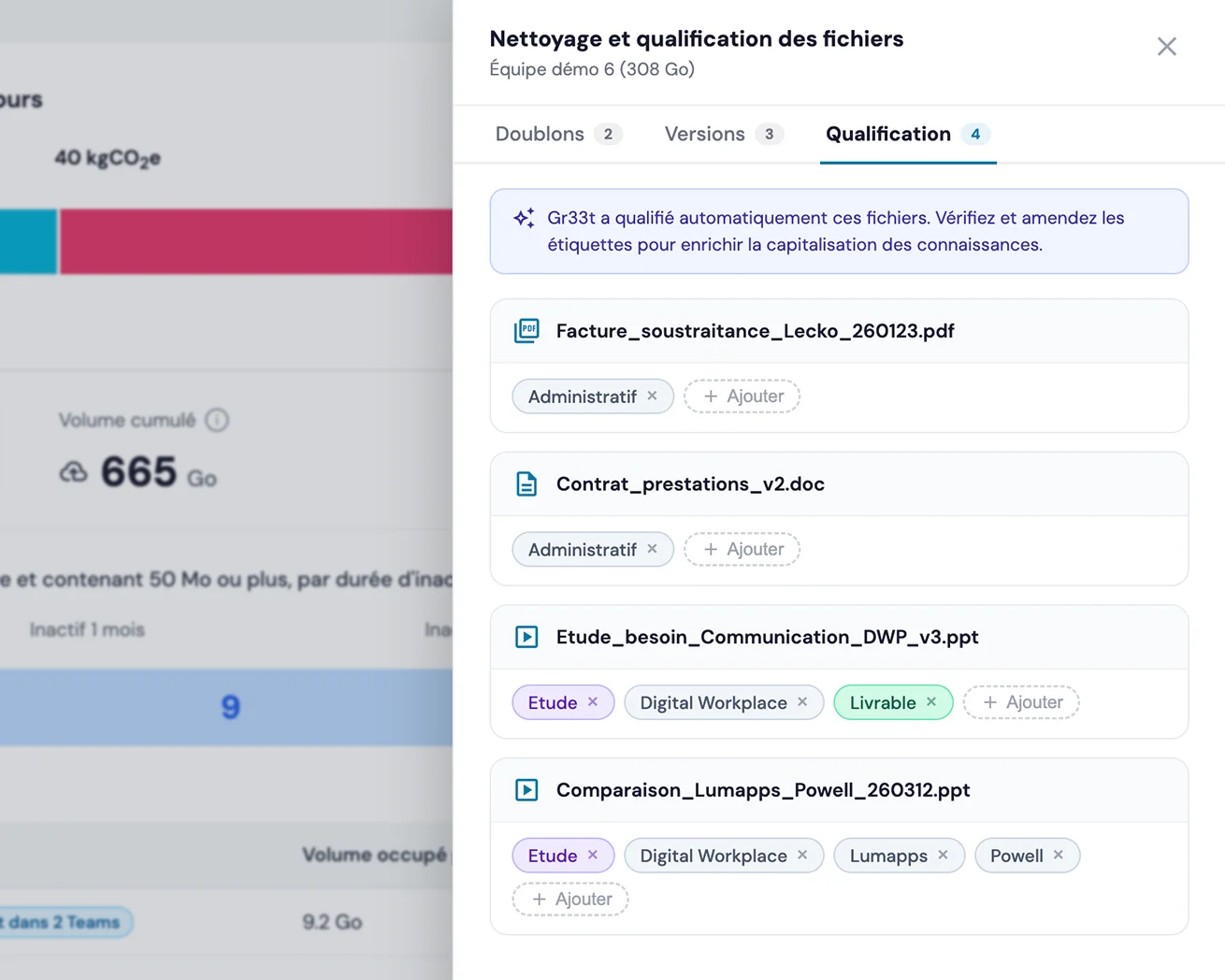
L'idée de qualifier automatiquement les documents avant le RAG semble simple. Elle ne l'est pas. Pour décider quel document mérite d'être indexé, il faut d'abord pouvoir observer l'ensemble du patrimoine documentaire : libellés, chemins, formats, tailles, dates, propriétaires, droits d'accès, doublons. Sans cet inventaire complet et tenu à jour, aucune qualification fine n'est possible.
Or indexer tous les documents d'un patrimoine Microsoft 365 ou Google Workspace n'est pas trivial. Il faut gérer le throttling de l'API Microsoft Graph, traiter les volumes (50 à 150 Go par collaborateur), suivre les modifications en temps réel, détecter les versions et les similarités. C'est un travail d'infrastructure long, peu visible, qui n'a de valeur qu'une fois fait.
Gr33t a investi plusieurs années sur ce verrou. La technologie indexe l'ensemble du patrimoine documentaire, le met à jour quotidiennement, et collecte pour chaque fichier une dizaine de métadonnées exploitables. Cet inventaire devient le socle sur lequel les règles métier peuvent enfin s'appliquer à grande échelle.
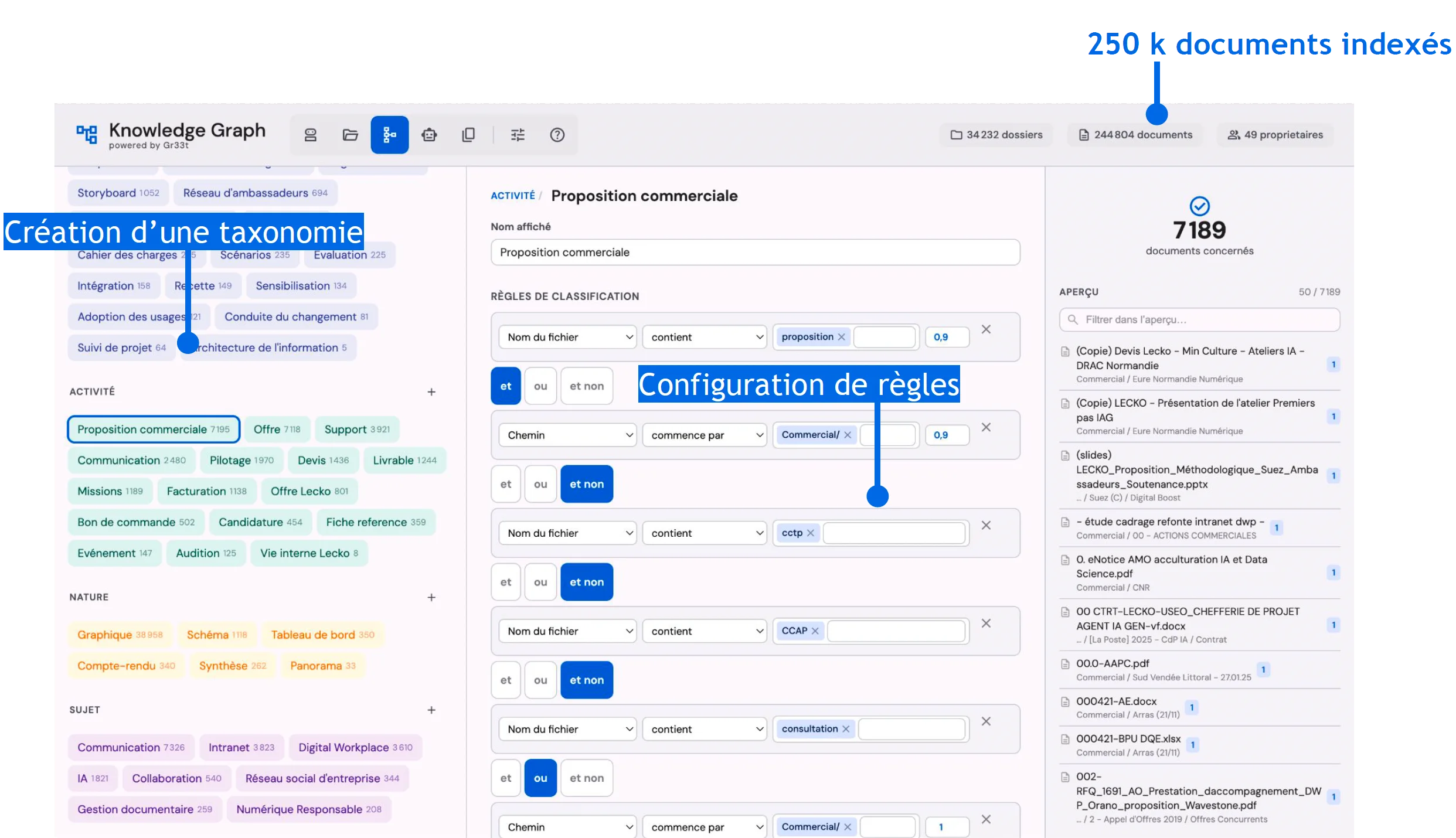
Le principe est simple : un métier définit une étiquette (par exemple Activité : Proposition commerciale) et y associe une règle exploitant les métadonnées collectées. Cette règle qualifie automatiquement tous les documents existants et futurs qui correspondent. Une personne définit, des milliers de documents bénéficient.
Une fois la taxonomie configurée, le métier décide quels périmètres alimentent quel pipeline RAG. Un agent IA pour les commerciaux exploitera les propositions commerciales, devis, livrables. Un agent IA pour les consultants exploitera les études, panoramas, synthèses. Chaque pipeline est nourri par une sélection précise, fraîche au jour le jour, sans dépendre de la discipline individuelle de classement.
Dans le cas Lecko, 4 pipelines actifs sélectionnent 3 852 documents uniques sur les 250 000 du patrimoine, soit moins de 2 % du volume, mais 100 % de la matière utile.
Activité : Proposition commerciale proposition,
propale,
devis Commercial consultation,
bdc,
facture Proposition commerciale parmi 250 000 documents indexés.
Pendant vingt ans, le Knowledge Management a fonctionné sur un postulat : si chacun classe correctement ses documents, l'entreprise saura. Le postulat était noble. Il n'a jamais tenu.
Il n'a pas tenu parce qu'il s'appuyait sur un effort individuel répété, dont les bénéfices vont aux autres. Demander à un consultant senior de tagger ses livrables, à un responsable produit de qualifier ses dossiers, à un commercial de classer ses propositions : c'est imposer un travail dont la valeur est diluée dans le collectif.
Avec le RAG, ce schéma revient. Mais l'IA ne pardonne pas l'inconstance, quand les sources ne sont plus à jour, elle hallucine et déçoit.
La sortie n'est pas dans une nouvelle politique de classement. Elle est dans un système qui qualifie à la place de l'humain, en s'appuyant sur ce que les documents disent d'eux-mêmes : leur nom, leur place, leur format, leur fraîcheur.
Gr33t n'est pas un agent IA. C'est la couche qui prépare la matière documentaire en amont des agents, quelle que soit la solution que vous avez retenue ou retiendrez. Microsoft Copilot, ChatGPT Enterprise, une Digital Workplace augmentée (LumApps, Powell, Elium), un RAG maison : Gr33t alimente l'un comme l'autre.
Vous déployez Copilot largement et constatez le plafond de pertinence dû à la pollution des documents de travail. Gr33t qualifie en amont les sources, et vous configurez Copilot pour interroger un ensemble qualifié plutôt que tout M365. Le coût ne baisse pas (les licences sont les mêmes), mais la pertinence remonte significativement.
Vous avez fait le choix d'une alternative à Microsoft pour des raisons d'indépendance, de coût ou de souveraineté. Gr33t devient votre source de vérité documentaire : il alimente votre RAG avec une matière qualifiée, à jour, et 10 à 50 fois moins volumineuse que le patrimoine brut.
Vous exploitez LumApps, Powell ou Elium pour le portail collaborateur, avec des fonctions IA intégrées. Gr33t fournit à ces plateformes la matière documentaire qualifiée, sans dépendre de leurs propres systèmes de classement.
Les experts métiers ne sont plus mobilisés pour trier. Une personne définit une règle, des milliers de documents sont qualifiés. La fraîcheur des sources est garantie par l'actualisation quotidienne.
La taxonomie ajoutée aux documents priorise les chunks lors du reranking. Le LLM dispose d'indications contextuelles (chemin, format, propriétaire) pour interpréter le corpus. Moins d'hallucinations, plus de précision.
Le pipeline RAG traite 20 à 50 fois moins de documents. Indexation initiale, ré-indexation hebdomadaire, stockage vectoriel : tous les postes de coût baissent dans cette proportion. Et l'empreinte environnementale aussi.
Votre connaissance n'est plus enfermée dans M365 ou Google Workspace. Vous choisissez votre LLM, votre RAG, votre fournisseur cloud, et changez si nécessaire, sans repartir de zéro sur la qualification.
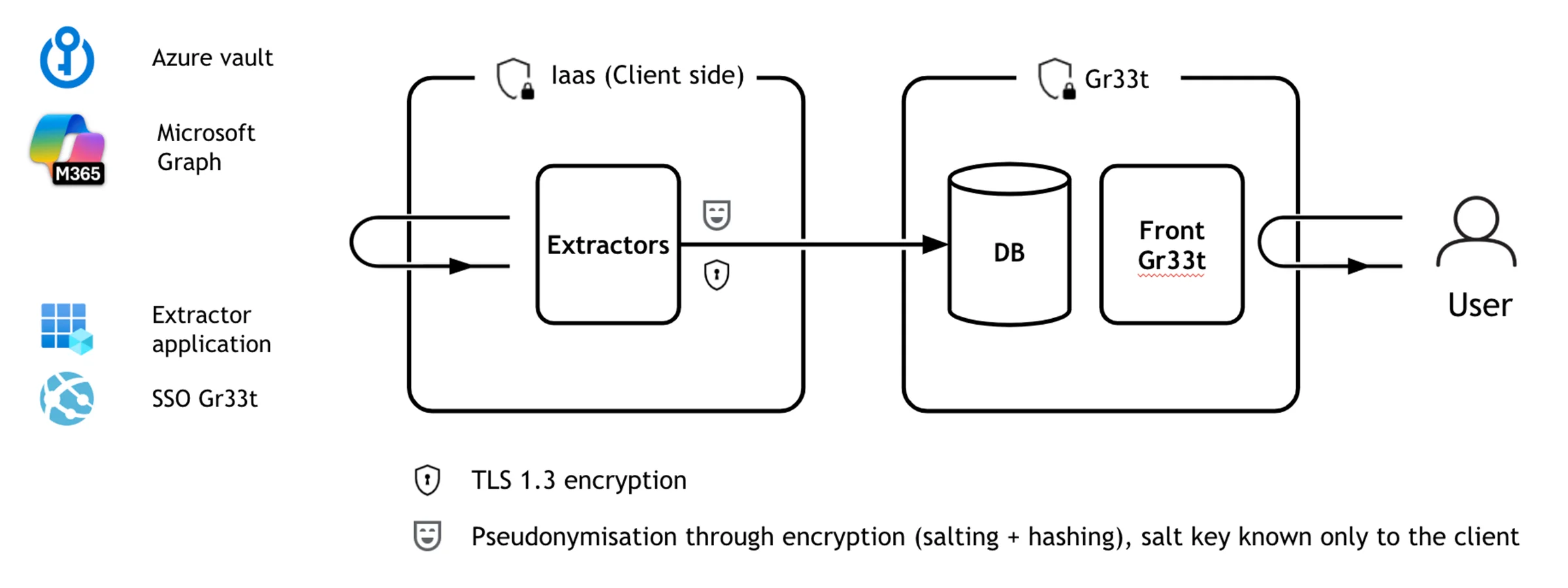
L'accès à l'ensemble du patrimoine documentaire impose une vigilance particulière. Gr33t opère en IaaS côté client : les extracteurs sont déployés dans l'infrastructure du client, en VM sans connexion entrante. Le client conserve la maîtrise complète de la sécurité de son tenant. Côté Gr33t, seules les métadonnées qualifiées circulent, pas les contenus de documents. Le knowledge graph reste à tout moment exportable et réversible, aucune dépendance enfermante.





Le déploiement de l'IA dans l'entreprise crée une tension sur les équipes. La pertinence de l'IA pre-RAG facilite son adoption, et Recovery mesure l'impact réel sur les rythmes de travail.
Découvrir Gr33t RecoveryLa qualification documentaire pour l'IA est l'extension naturelle de la sobriété numérique. Le même geste sert deux causes.
Découvrir Gr33t Numérique Responsable45 minutes pour parcourir un knowledge graph Gr33t sur un patrimoine documentaire réel, configurer une première taxonomie, et imaginer comment pre-RAG s'insère dans votre architecture IA.